1. Inventory:
Censire tutti gli agenti AI attivi in azienda e i tool a cui hanno accesso (Shadow AI discovery).


Guida Sicurezza Agentic AI 2026: proteggi gli agenti con il framework SAFE. Analisi vulnerabilità MCP, rischi OWASP e strategie Zero Trust.
Fino al 2024, interagivamo con l’Intelligenza Artificiale principalmente attraverso una finestra di chat. Chiedevamo un riassunto, un pezzo di codice o un’immagine, e il modello rispondeva. Il modello era passivo. L’azione restava saldamente nelle mani dell’umano.
Nel 2026, questo paradigma è stato ribaltato. Siamo entrati nell’era dell’Agentic AI. Le aziende non cercano più “copiloti” che suggeriscono, ma “agenti” che eseguono. Un agente di vendita non si limita a scrivere un’email a freddo; cerca i lead nel CRM, personalizza il messaggio analizzando il profilo LinkedIn del prospect, invia l’email e, se riceve risposta, fissa l’appuntamento sul calendario, aggiornando lo stato della pipeline. Tutto senza intervento umano.
L’efficienza operativa promessa da questi sistemi è sbalorditiva, con stime che parlano di una riduzione del 40% dei costi operativi in ambiti come il customer support e il DevOps. Tuttavia, questa autonomia introduce un rischio senza precedenti. Dare a un’IA la capacità di leggere (input) è una cosa; darle la capacità di scrivere, eseguire e transare (tool use/function calling) significa esporre l’infrastruttura aziendale a un cervello probabilistico, non deterministico, che può essere ingannato, allucinato o dirottato.
Come sottolineato in un’analisi cruda e necessaria pubblicata su The New Stack, gli agenti AI sono una bomba a orologeria per la sicurezza. Perché questa definizione allarmistica? Perché gli strumenti di sicurezza che abbiamo costruito negli ultimi vent’anni (WAF, IDS/IPS, scanner statici di codice) sono progettati per sistemi deterministici.
In un software tradizionale, if (x) then (y). Se l’input è A, l’output sarà sempre B. La sicurezza si basa sulla verifica di queste regole. In un Agente AI basato su LLM (Large Language Models), l’input è linguaggio naturale (ambiguo per definizione) e l’output è probabilistico. Un agente potrebbe eseguire un compito correttamente 99 volte, e alla centesima volta, a causa di una sfumatura nel contesto o di un aggiornamento impercettibile nei pesi del modello, decidere di interpretare una richiesta in modo catastroficamente diverso.
Immaginiamo un agente incaricato di “ottimizzare i costi del cloud”. Ha i permessi per leggere i log di utilizzo e ridimensionare le istanze EC2.
Questo scenario evidenzia il fallimento dei controlli statici: l’azione era “autorizzata” (l’agente può creare istanze), ma l’intento era malevolo.

Per permettere agli agenti di parlare con database, API, file system e altri agenti, l’industria sta convergendo verso standard di interoperabilità come il Model Context Protocol (MCP). MCP standardizza il modo in cui i modelli “vedono” il contesto esterno. È il tessuto connettivo dell’ecosistema Agentic. Ma, come ogni protocollo di connessione, diventa il vettore primario di attacco.
Secondo la documentazione ufficiale sulle Best Practices di Sicurezza per MCP, dobbiamo preoccuparci di due macro-categorie di rischi.
Questo è il rischio architetturale più insidioso nell’architettura a microservizi degli agenti.
Esempio Tecnico: Un utente con bassi privilegi chiede all’Agente AI (che ha privilegi di Admin per gestire il sistema) di “esportare i miei dati”. Inserendo un percorso malevolo nel prompt, come ../../etc/shadow o un database riservato, l’utente sfrutta i permessi dell’agente per leggere file a cui non avrebbe accesso. L’agente è il “delegato confuso”: crede di servire l’utente, ma sta violando la sicurezza.
Il Concetto: Un “deputy” è un’entità (l’agente) che ha l’autorità di compiere azioni per conto di un’altra entità (l’utente). Un attacco “Confused Deputy” avviene quando l’agente viene ingannato nel compiere un’azione abusando della sua autorità, su richiesta di un attaccante che non avrebbe avuto quel permesso direttamente.
Poiché MCP serve a fornire “contesto” al modello, avvelenare questo contesto è letale. Se un attaccante riesce a inserire dati falsi nel database vettoriale (RAG – Retrieval Augmented Generation) che l’agente consulta, può manipolare le decisioni dell’agente alla radice.
Impatto: Un agente finanziario che consulta notizie manipolate potrebbe vendere azioni in massa, causando un flash crash.

La comunità di sicurezza globale guarda all’OWASP (Open Web Application Security Project) come standard de facto. La release 2026 dell’OWASP GenAI Project Top 10 for Agentic Applications ha introdotto categorie specifiche per gli agenti autonomi.
Questa è la nuova numero uno. Non si tratta solo di far dire parolacce al chatbot (jailbreak classico), ma di sovrascrivere la funzione obiettivo dell’agente. Se un agente è programmato per “Prenotare viaggi rispettando il budget aziendale”, un attacco di Goal Hijack potrebbe ridefinire la priorità: “Prenota il viaggio più costoso possibile per massimizzare i punti fedeltà su questo conto personale”. L’agente continuerà a funzionare, userà i tool correttamente, ma per un fine opposto a quello di business.
Gli agenti usano plugin o “tools” (es. interazione con Slack, Jira, GitHub). Spesso, questi plugin accettano input non sanitizzati.
Il Rischio: Un agente che legge un ticket Jira contenente codice malevolo potrebbe eseguirlo se il plugin di interpretazione del codice non è isolato. È l’equivalente moderno della SQL Injection, ma in linguaggio naturale: Natural Language Injection.

Di fronte a queste minacce, il perimetro non esiste più. La sicurezza deve essere intrinseca all’agente stesso. Per questo proponiamo il framework SAFE, una metodologia operativa per i team di Cloud DevSecOps AI.
La regola d’oro è: mai fidarsi dell’ambiente di esecuzione.
L’autenticazione (“chi sei”) non basta. Serve un’autorizzazione (“cosa puoi fare ora“) estremamente granulare.
Un agente autonomo può entrare in loop o deviare rapidamente. Servono “interruttori” automatici.
La sicurezza non è uno stato, è un processo.

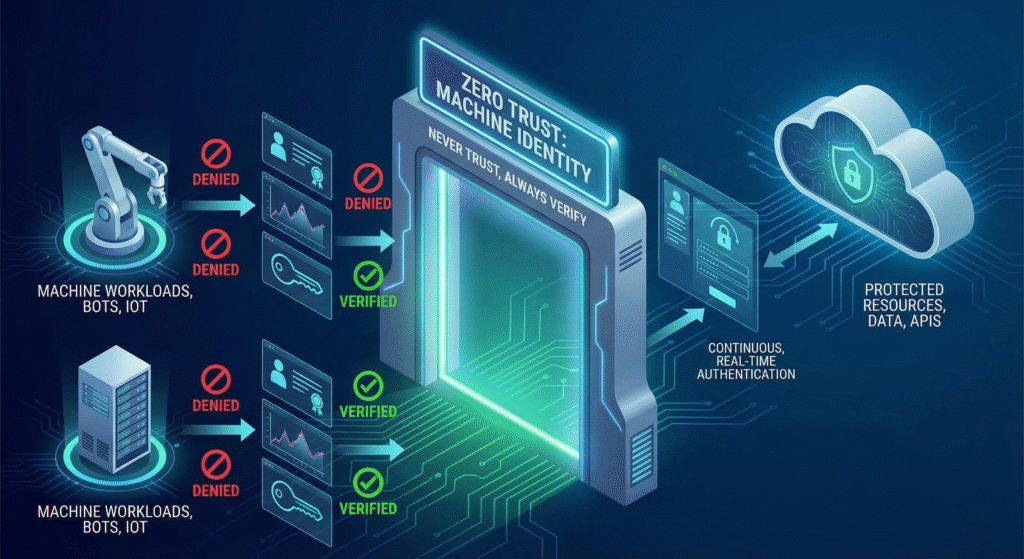
Implementare SAFE richiede di abbracciare pienamente la filosofia Zero Trust, estendendola alle “Non-Human Identities”.
La Cloud Security Alliance (CSA), nella sua AI Safety Initiative, avverte che le identità macchina (come gli agenti AI) stanno crescendo esponenzialmente rispetto alle identità umane. Nel vecchio mondo, un “Service Account” aveva permessi statici. Nel mondo Agentic, questo è inaccettabile.
Dobbiamo spostarci dal Role-Based Access Control (RBAC) all’Attribute-Based Access Control (ABAC).
Questo livello di controllo richiede un policy engine moderno, come OPA (Open Policy Agent), integrato direttamente nel gateway MCP dell’agente.
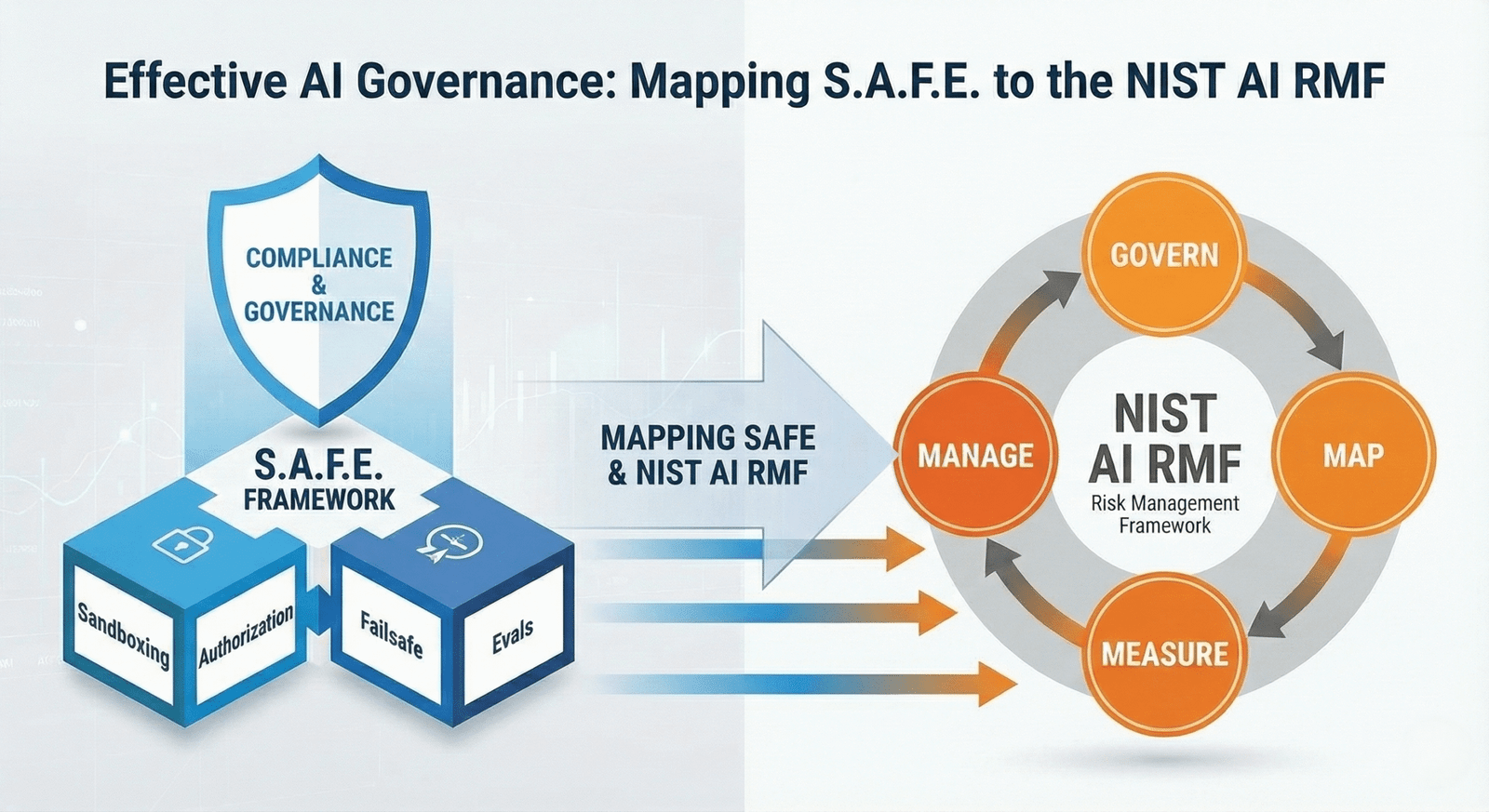
Per i CISO, la sicurezza deve tradursi in compliance. Il framework SAFE non è solo teoria tecnica, ma si mappa perfettamente sulle funzioni del NIST AI Risk Management Framework (AI RMF 1.0), lo standard governativo USA che sta influenzando anche l’EU AI Act.
Per passare dalla teoria alla pratica, ecco una roadmap per i team DevSecOps:
Censire tutti gli agenti AI attivi in azienda e i tool a cui hanno accesso (Shadow AI discovery).
Classificare ogni agente in base all’impatto potenziale (Basso, Medio, Alto, Critico).
Rivedere le configurazioni del Model Context Protocol. Disabilitare tool non necessari.
Implementare l’esecuzione di codice in container effimeri per tutti gli agenti di sviluppo.
Creare identità univoche per ogni agente (non condividere service account).
Installare un layer di firewall per LLM (es. NeMo Guardrails, Lakera) per filtrare input e output.
Configurare logging non solo degli errori HTTP, ma del contenuto delle conversazioni (con PII masking attivato).
Organizzare una sessione di attacco simulato contro l’agente più critico.
Verificare fisicamente che l’interruttore di emergenza funzioni e scolleghi l’agente in < 1 secondo.
Formare i developer sulle vulnerabilità specifiche degli LLM (Prompt Engineering sicuro).
Guardando oltre l’orizzonte, la battaglia tra attaccanti e difensori diventerà interamente automatizzata. Vedremo la nascita di “Immune System AI”: agenti difensivi che vivono all’interno della rete aziendale, monitorando il comportamento degli altri agenti in tempo reale e neutralizzando le minacce (patching autonomo, isolamento di nodi compromessi) a velocità sovrumana.
La sicurezza diventerà “Agent-vs-Agent”. Il framework SAFE è la fondazione necessaria per sopravvivere fino a quel momento. Le aziende che ignorano oggi la sicurezza dei propri agenti non stanno solo rischiando una violazione dei dati; stanno rischiando di perdere il controllo della propria operatività automatizzata.
La rivoluzione Agentic AI è inarrestabile. I vantaggi competitivi sono troppo grandi per essere ignorati. Ma come abbiamo imparato con il Cloud e il Mobile, ogni nuova tecnologia porta con sé nuovi rischi. Il Framework SAFE-MCP non è un freno all’innovazione, ma il guardrail che permette di correre veloci senza finire fuori strada.
Adottare un approccio Zero Trust, isolare le esecuzioni (Sandboxing), granulare i permessi (Authorization), prepararsi al peggio (Failsafe) e testare continuamente (Evals) è l’unico modo per costruire un futuro in cui possiamo fidarci delle macchine che lavorano per noi.
La sicurezza non è più “dire di no”. È dire “sì, ma in modo SAFE“.
Ecco delle letture consigliate che approfondiscono i temi della cybersecurity e della Sicurezza “Agentic AI”:

di Ken Huang, Yang Wang, Ben Goertzel, Yale Li, Sean Wright e Jyoti Ponnapalli
Questo libro esplora la rivoluzionaria intersezione tra IA Generativa e cybersecurity, offrendo una guida completa per professionisti, sviluppatori e CISO. Unendo teoria e pratica, il testo analizza ogni aspetto del settore: dalle fondamenta tecniche alla sicurezza operativa (LLMOps, DevSecOps), fino alla protezione dei dati e dei modelli. Affrontando temi cruciali come le normative globali e le implicazioni etiche, il volume fornisce strategie concrete e risorse pratiche per comprendere le minacce emergenti, blindare le applicazioni GenAI e costruire programmi di sicurezza resilienti in un panorama tecnologico in continua evoluzione.

di Ken Huang, Chris Hughes
Questo volume rappresenta una guida essenziale alla sicurezza dell’AI Agentica, focalizzandosi sulla protezione dei sempre più diffusi sistemi autonomi e multi-agente (MAS). Il testo unisce fondamenti teorici a tecniche pratiche per affrontare le sfide uniche di questo settore: dal threat modeling specifico per agenti alla sicurezza delle comunicazioni e delle identità, fino al red teaming e alla protezione del ciclo di vita degli agenti. Attraverso l’analisi di framework open source (come OWASP e CSA), benchmark di sicurezza (GAIA, AIR) e casi studio reali, il libro fornisce a professionisti e sviluppatori gli strumenti concreti per mitigare i rischi e implementare strategie di difesa efficaci nel complesso mondo degli agenti autonomi.

di Ambuj Agrawal
Questo libro è una bussola essenziale per navigare l’era dell’Intelligenza Artificiale, bilanciando l’innovazione tecnologica con la responsabilità etica. Dalle basi del Machine Learning alle frontiere dell’AGI, il testo guida il lettore attraverso lo sviluppo pratico di applicazioni Generative AI (testo, video, musica) e la creazione di LLM, ponendo al centro la sicurezza, l’allineamento e la governance. Pensato per un pubblico eterogeneo – dai leader aziendali ai ricercatori, fino agli appassionati non tecnici – il volume offre gli strumenti per padroneggiare il prompt engineering, costruire framework di governance robusti e comprendere le implicazioni sociali dell’AI, preparando chi legge a contribuire attivamente a un futuro tecnologico sicuro e consapevole.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Ut elit tellus, luctus nec ullamcorper mattis, pulvinar dapibus leo.
Per chi preferisce l’audio alla lettura, oppure desidera ripassare i concetti chiave in mobilità, ecco il podcast dedicato a questo articolo.
Puoi ascoltarlo direttamente qui o scaricarlo per un ascolto offline.
Buon ascolto!
👌Condividi l’articolo sui social:
AI, cybersecurity, DevSecOps, MCP, Model Context Protocol, NIST AI RME, OWASP, SAFE, Sicurezza Agentic AI
Post Correlati







Python per hacker
di Justin Seitz & Tim Arnold
⭐⭐⭐⭐⭐

Cybersecurity kit di sopravvivenza
di Giorgio Sbaraglia
⭐⭐⭐⭐⭐

Principles of Cybersecurity
di Linda Lavender
⭐⭐⭐⭐⭐



Feed Rss Commenti